
グラフ作成
前回も使用したIrisデータセットをもとにグラフをいくつか作成してみたいと思います。
エクセルでもグラフは作れるし、わざわざPythonを使う必要あるの?と感じるかもしれません。
単純なグラフを作るだけならそこまでメリットは感じませんが、エクセル外のデータと連携したり、データを機械学習に使ったり…と発展させていくことができます。将来的にこういった機能を使っていきたい場合はPythonに分があります。
それではグラフを作成していきましょう。
散布図作成
散布図とは二つの項目の相関関係を示すグラフです。アヤメのがくの幅と長さの相関関係をグラフにしてみます。
import matplotlib.pyplot as plt // matplotlibを読み込みpltとする
plt.scatter(xl("IrisDataSet[sepal_length]"), xl("IrisDataSet[sepal_width]")) //x軸にsepal_lengthを、y軸にsepal_widthを指定して散布図を作成
plt.xlabel('sepal_length') // x軸のラベル
plt.ylabel('sepal_width') // y軸のラベル
plt.title('Sepal length and width analysis')// タイトルをつける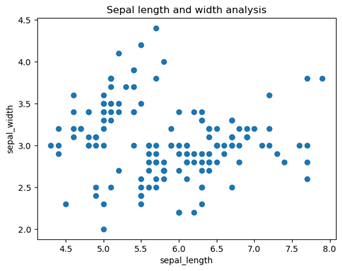
このようにグラフが作成されます。
ここではmatplotlibというグラフ作成用のライブラリを使用しました。
ペアプロット作成
ペアプロットとは、データを列ごとに散布図とヒストグラムにして一度に描写する機能です。ひとまず作成してみましょう。
from pandas.plotting import scatter_matrix // pandasライブラリのscatter_matrix関数をインポート
sample_df = xl("IrisDataSet[#すべて]", headers=True)// Irisデータセットを読み込み
columns_to_plot = ["sepal_length", "sepal_width", "petal_length", "petal_width"] // プロットするためにIrisデータセットの列を指定する
categories = sample_df["species"].unique() // 花の種類(species )からユニークな値を取得しカテゴリとする
colors = {category: i for i, category in enumerate(categories)} // 花の種類ごとに異なる色を割り当てる
scatter_matrix(sample_df, c=sample_df["species"].apply(lambda x: colors[x]), figsize=(6, 6), alpha=0.8) // scatter_matrixでプロットする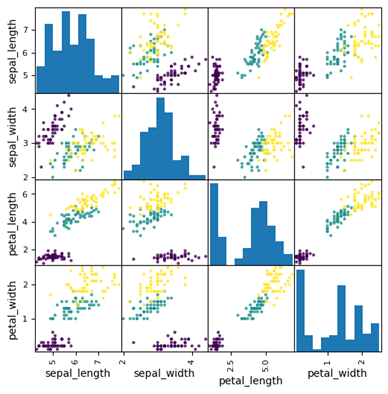
ここではpandasというライブラリを使用しました。このようにデータ解析のライブラリが充実しており、比較的シンプルに書けるのがPythonの特徴です。
Copilot について
Copilot(Microsoftが提供する生成AI)にPythonコードを書いてもらう機能も同時に公開されています。(利用には別途費用が必要になりますが)
Pythonに明るくなくても、こういうデータ解析がしたい、と入力するだけで自動でコードを書いてくれるようです。データ解析をしたいが、Pythonの習得はちょっと手が回らない…という方にはうれしい機能ですね。
<< PREV
NEXT>>
