
以前のブログで、文字を音声に変換するサービスをご紹介しました(⇒自動音声生成サービス)が、今回は逆の音声を文字にする仕組みについてのお話です。
みなさんは音声のテキスト変換、Speech To Textをご存知でしょうか?
その名の通り、人が喋っている音声を認識してテキストに変換するというものです。
いわゆる音声認識サービスとして、身近なものではSiriやAlexaのようなものがあります。
これらは口頭で指示を出すとその内容を解析して、内容に応じて何らかのアクションを起こしてくれるものです。
Speech To Textはそれらと同様、音声情報を解析し、その内容をテキスト化して返してくれるものです。
現在3大クラウドと言われているGCP(Google)、Azure(Microsoft)、AWS(Amazon)でAPIとして個人でもSpeech To Textが使える様になっています。
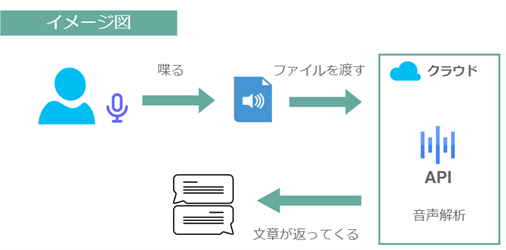
実際に、弊社の年始朝礼の録音音声を変換して、結果を見てみました。
※前提として、固有名詞などの単語や、話者の声の特徴等をAPI側に学習させていません
完全プレーンな状態でのテキスト変換ですので、学習次第によってさらに精度は向上すると思います。
※今回はリアルタイムではなく録音した音声から変換を行っています。
まず、全体的な所感としては、10分超4000文字程度の変換があっという間にできてしまいます。
これは聞きながら文字起こしするとしてもなかなか書ききれず、1~2時間かけて補完して…ということが必要になる作業でしたが、そこが大幅短縮になります。
ただし「あー」とか「えーと」もそのまま文字起こしされてるので、そのあたりの清書は必須です。
ただ、やはり英語に比べて、日本語の変換は難しいのかな、と結果を見ていると感じます。
たとえば下記のような誤変換がありました。
去年の松から今年にかけては
書道を間違えたために
上から順に、「去年の末」「初動」の誤変換になります。このあたりを見ると、文脈を察して熟語を選ぶ、ということはあまり得意ではないのかもしれません。
AIの進化によって改善していくことを期待したいところです。
ちょっとだけ TV でお話ししたように
これは一見正しそうですが、実際にはTVではなくTeamsと言っていたので、音声解析が気を回しすぎた結果のようです。
天守閣の QR 孵化するの中でその中で主役の伝説が見れるような
この辺はいかにも自動変換らしい、文脈も何もあったものじゃないワードチョイスですね。
何点ですかねへんのおこじゅんよくの分割家の事が進んだりしんですが
これは何度読んでも元々何と言っていたのか謎です。
このように、自動変換だけで文字起こし完成、には、とりわけ日本語はまだ遠そうではあります。
しかし、今回は利用していませんが、最新のAPIでは、
- 優先する単語(たとえば、「えいせい」という音声を変換する際、「衛星」ではなく「衛生」を優先するように指定する。上記の誤変換群もこれがあれば解決しそうですね)の設定ができる
- 音声の内容のジャンルを選べる(医療系、建築系のようにジャンルを選ぶことで単語の選択精度をあげてくれる)など
など、技術としてもどんどん進化しているようです。
また、会議の録音のような複数人の会話を文字起こしする場合、オプションで誰の発言かを区別してくれるようなものもあり、利用者が増えていけば結果のクオリティの向上も期待できます。
<< PREV
NEXT>>
